Connecting the dots: how Private Service Connect saved us from network topology hell

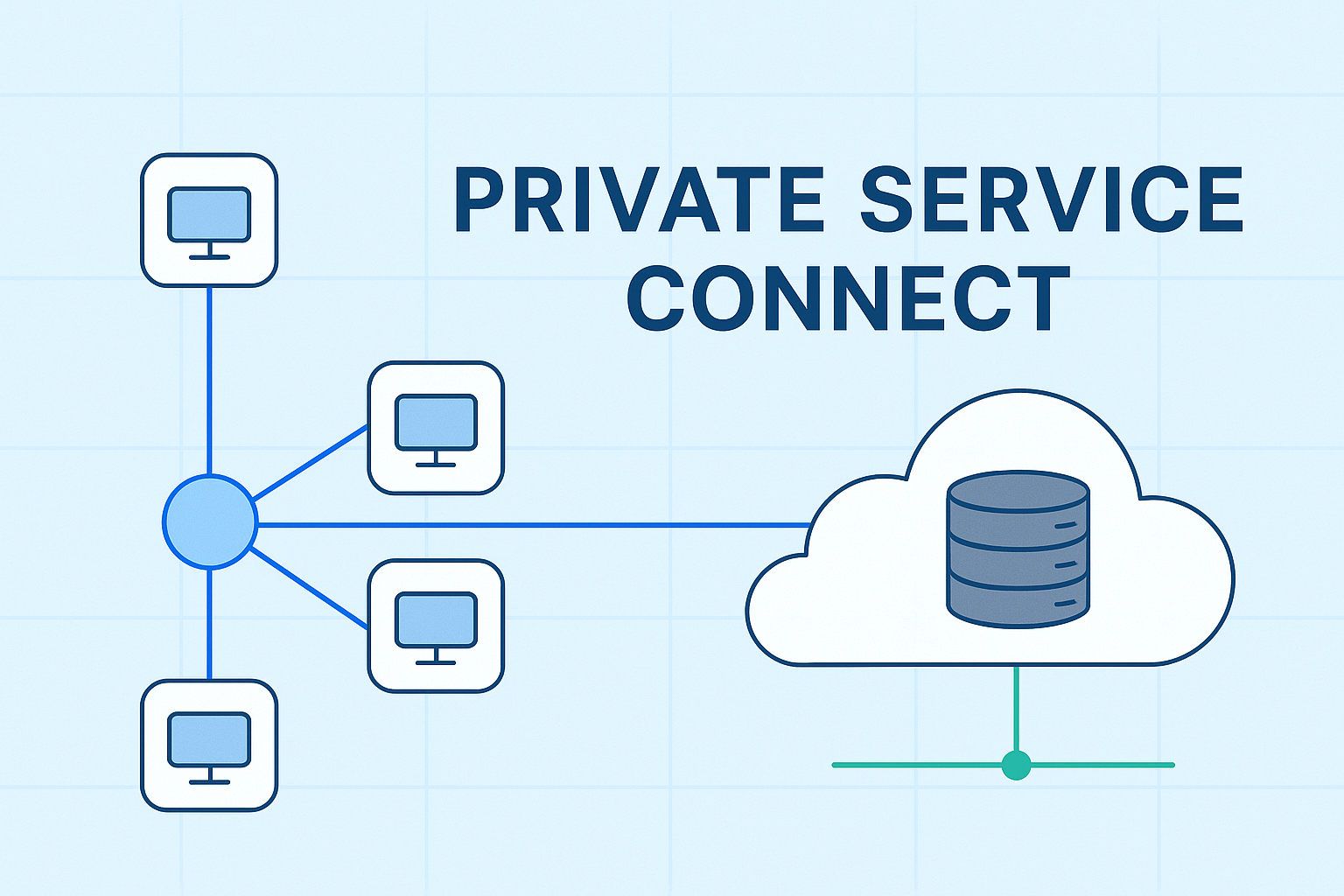
For one of our AI applications we needed to be able to interact with a centralized PostgreSQL vector database from five different production projects. By our standards we needed this to be fully private, low-latency, and eventually scale to 100+ environments worldwide. Initially we looked at VPC peering but quickly concluded that it would become very complex.
This is how Private Service Connect turned what would have been a networking mess into something surprisingly straightforward.
The problem
At Silverfin, each production environment runs in its own isolated GCP project which is great for security, terrible for sharing resources. This means that this AI application needed to run in five different European projects, all talking to the same PostgreSQL database for vector embeddings.
VPC peering was the obvious choice, except it creates an N×N mesh. Five projects = 10 peering connections. Scale to 100 projects and you're at 4,950 connections. Not realistic.
The database couldn't have a public IP. We briefly considered a VPN setup but that felt like going backwards. However Private Service Connect seemed exactly what we needed.
What is Private Service Connect anyway
PSC lets you expose a service (like a load balancer) as a service attachment, then consumers create forwarding rules that point to it. The consumer gets a local IP address in their VPC that magically routes to your service. No VPC peering, no shared address space, no cross-project routes to maintain.
The main thing for us is that consumer projects have their own IP addresses for the same service. So one environment might use 10.1.0.50 while another might also use 10.1.0.50. Since both are in a different VPC this does not matter.
Setting it up
We're running a self-managed PostgreSQL cluster in a dedicated vectordb project.
The service attachment is pretty straightforward (we use OpenTofu for everything):
resource "google_compute_service_attachment" "vectordb" {
name = "vectordb"
project = "vectordb-project"
region = "europe-west1"
connection_preference = "ACCEPT_MANUAL"
enable_proxy_protocol = false
nat_subnets = [google_compute_subnetwork.europe-west1-psc.id]
target_service = "projects/vectordb-project/regions/europe-west1/forwardingRules/postgres"
dynamic "consumer_accept_lists" {
for_each = local.vectordb_psc_attached_projects
content {
project_id_or_num = consumer_accept_lists.value
connection_limit = 2
}
}
}We use manual acceptance (ACCEPT_MANUAL) so projects can't just randomly connect. The connection_limit of 2 per project gives us room for redundancy. We carved out a /24 range (192.168.10.0/24) for PSC NAT subnets, which turned out to be useful later when debugging connection issues.
The consumer side
On the consumer side, each production project gets a forwarding rule. The application code has no idea it's doing anything special. As far as the AI application knows, it's connecting to a regular internal IP address:
resource "google_compute_forwarding_rule" "vectordb-psc" {
for_each = local.vectordb_psc_attached_projects
project = each.key
name = "vectordb"
region = "europe-west1"
load_balancing_scheme = ""
network = "default"
target = google_compute_service_attachment.vectordb.id
ip_address = data.google_compute_address.ai-quick-mapper-postgresql[each.key].id
allow_psc_global_access = true
}That empty string in load_balancing_scheme? Turns out PSC requires an empty string, not null, not omitted—an actual empty string. Documentation is great, but sometimes you need to learn through frustration.
Cloud SQL version
Since we also have some Cloud SQL workloads we can leverage native PSC support quite easily:
resource "google_sql_database_instance" "vectordb" {
name = "vectordb"
project = "vectordb-project"
region = "europe-west1"
settings {
ip_configuration {
ipv4_enabled = false
private_network = "projects/vectordb-project/global/networks/default"
ssl_mode = "ENCRYPTED_ONLY"
psc_config {
psc_enabled = true
allowed_consumer_projects = var.private_service_connect_allowed_consumer_projects
}
}
}
# irrelevant parmateres omitted
}Cloud SQL handles the service attachment, load balancing, HA, all of it.
Performance
We ran some benchmarks comparing PSC to direct VPC connectivity. The overhead was under 1ms, which for our use case (semantic search queries averaging 50ms) doesn't matter. Connection establishment takes about 100ms initially, then gets cached. We've had over 1,000 concurrent connections without problems.
Scaling
Adding a new consumer project is one line of code:
locals {
vectordb_psc_attached_projects = toset([
"europe-west1-1-abc",
"europe-west1-2-def",
# ... existing projects ...
"europe-west1-6-pqr", # new project
])
}OpenTofu's for_each handles everything else: updating the service attachment, creating forwarding rules, provisioning IP addresses, storing secrets, IAM permissions. No manual networking changes.
Wrapping up
If you're building multi-project infrastructure on GCP, consider PSC instead of VPC peering. It works well for centralized databases, shared services, or anything that needs cross-project connectivity without the mesh complexity.
Our network topology is simpler now and adding new projects is trivial. When we scale to 100+ environments, the networking won't be the bottleneck.
References
- Google Cloud Private Service Connect Documentation
- Cloud SQL Private Service Connect
- Private Service Connect Best Practices
The Infrastructure team at Silverfin manages cloud infrastructure using infrastructure-as-code principles with OpenTofu. Our goal is to maintain 100+ production environments with a small team by treating infrastructure as cattle, not pets.